Latent Semantic Analysis (LSA) package





In brief
This Raku package, "ML::LatentSemanticAnalyzer", has different functions for computations of
Latent Semantic Analysis (LSA) workflows
(using Sparse matrix Linear Algebra.) The package mirrors
the Mathematica implementation [AAp1].
(There is also a corresponding implementations in Python and R; see [AAp2, AAp3].)
The package provides:
- Class
ML::LatentSemanticAnalyzer - Functions for applying Latent Semantic Indexing (LSI) functions on matrix entries
- "Data loader" function for obtaining a dataset of ~580 abstracts of conference presentations
Installation
To install from Zef ecosystem:
zef install ML::LatentSemanticAnalyzer
To install from GitHub use the shell command:
zef install https://github.com/antononcube/Raku-ML-LatentSemanticAnalyzer.git
LSA workflows
The scope of the package is to facilitate the creation and execution of the workflows encompassed in this
flow chart:
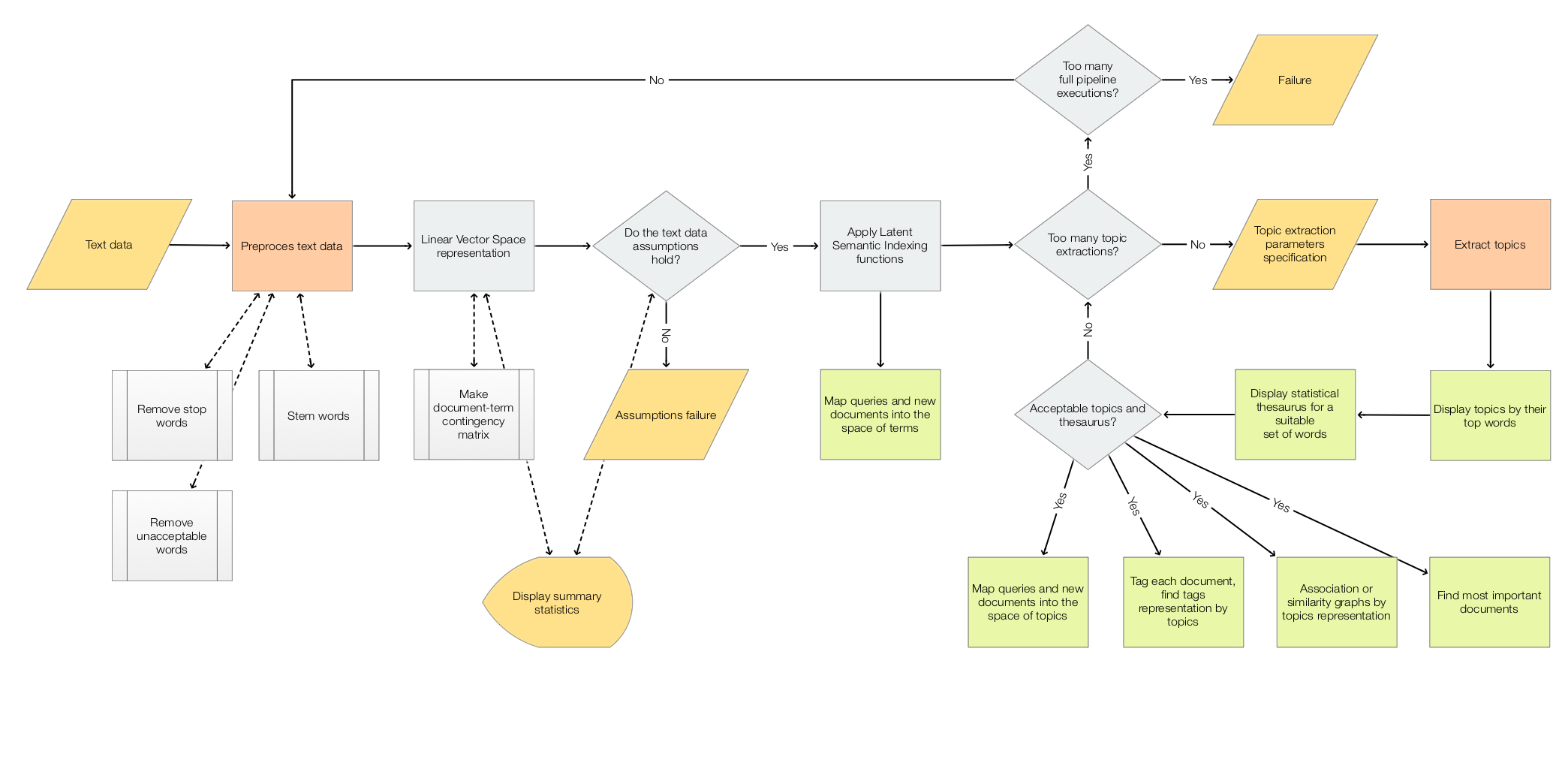
For more details see the article
"A monad for Latent Semantic Analysis workflows",
[AA1].
Usage example
Here is an example of a LSA pipeline that:
- Ingests a collection of texts
- Makes the corresponding document-term matrix using stemming and removing stop words
- Extracts 40 topics
- Shows a table with the extracted topics
- Shows a table with statistical thesaurus entries for selected words
use ML::LatentSemanticAnalyzer;
use Lingua::EN::Stem::Porter;
# Collection of texts
my @dsAbstracts = get-abstracts-dataset();
my %docs = @dsAbstracts.map(*<ID>) Z=> @dsAbstracts.map(*<Abstract>);
say %docs.elems;
# Remove non-strings
my %docs2 = %docs.grep({ $_.value ~~ Str:D });
say %docs2.elems;
# Stemmer object (to preprocess words in the pipeline below)
say &porter.WHY;
# Words to show statistical thesaurus entries for
my @words = <notebook computational function neural talk programming>;
# Reproducible results (just within a session)
srand(12);
# LSA pipeline
my $lsaObj =
LatentSemanticAnalyzer.new
.make-document-term-matrix(docs => %docs2, :stop-words, :stemming-rules, :3min-length)
.apply_term_weight_functions(
global-weight-func => "IDF",
local-weight-func => "None",
normalizer-func => "Cosine")
.extract-topics(:40number-of-topics, :10min-number-of-documents-per-term, method => "SVD")
.echo-topics-interpretation(:12number-of-terms, :!wide-form)
.echo_statistical_thesaurus(
terms => @words.map(*.&porter),
:wide-form,
:12number-of-nearest-neighbors,
method => "cosine",
:echo)
This package is based on the Raku package
"Math::SparseMatrix", [AAp5]
The package
"ML::SparseMatrixRecommender", [AAp6]
also uses LSI functions -- this package uses LSI methods of the class ML::SparseMatrixRecommender.
Mathematica
The Raku pipeline above corresponds to the following pipeline for the Mathematica package
[AAp1]:
lsaObj =
LSAMonUnit[aAbstracts]⟹
LSAMonMakeDocumentTermMatrix["StemmingRules" -> Automatic, "StopWords" -> Automatic]⟹
LSAMonEchoDocumentTermMatrixStatistics["LogBase" -> 10]⟹
LSAMonApplyTermWeightFunctions["IDF", "None", "Cosine"]⟹
LSAMonExtractTopics["NumberOfTopics" -> 20, Method -> "NNMF", "MaxSteps" -> 16, "MinNumberOfDocumentsPerTerm" -> 20]⟹
LSAMonEchoTopicsTable["NumberOfTerms" -> 10]⟹
LSAMonEchoStatisticalThesaurus["Words" -> Map[WordData[#, "PorterStem"]&, {"notebook", "computational", "function", "neural", "talk", "programming"}]];
Python
Here is a corresponding Python pipeline with the package [AAp3]:
lsaObj = (LatentSemanticAnalyzer()
.make_document_term_matrix(docs=docs2,
stop_words=True,
stemming_rules=True,
min_length=3)
.apply_term_weight_functions(global_weight_func="IDF",
local_weight_func="None",
normalizer_func="Cosine")
.extract_topics(number_of_topics=40, min_number_of_documents_per_term=10, method="NNMF")
.echo_topics_interpretation(number_of_terms=12, wide_form=True)
.echo_statistical_thesaurus(terms=stemmerObj.stemWords(words),
wide_form=True,
number_of_nearest_neighbors=12,
method="cosine",
echo_function=lambda x: print(x.to_string())))
R
The package
LSAMon-R,
[AAp2], implements a software monad for LSA workflows.
LSA packages comparison project
The project "Random mandalas deconstruction with R, Python, and Mathematica", [AAr1, AA2],
has documents, diagrams, and (code) notebooks for comparison of LSA application to a collection of images
(in multiple programming languages.)
A big part of the motivation to make the Python package
"RandomMandala", [AAp4],
was to make easier the LSA package comparison.
Mathematica and R have fairly streamlined connections to Python, hence it is easier
to propagate (image) data generated in Python into those systems.
Code generation with natural language commands
Using grammar-based interpreters
The project "Raku for Prediction", [AAr2, AAv2, AAp8], has a Domain Specific Language (DSL) grammar and interpreters
that allow the generation of LSA code for corresponding Mathematica, Python, R, and Raku packages.
Here is Command Line Interface (CLI) invocation example that generate code for this package:
dsl-translation -t=Raku 'create from aDocs; apply LSI functions IDF, None, Cosine; extract 20 topics; show topics table'
# ML::LatentSemanticAnalyzer.new(aDocs)
# .apply-term-weight-functions(global-weight-func => "IDF", local-weight-func => "None", normalizer-func => "Cosine")
# .extract-topics(number-of-topics => 20)
# .echo-topics-table( )
NLP Template Engine
Here is an example using the NLP Template Engine, [AAr2, AAv3, AAp9]:
use ML::NLPTemplateEngine;
concretize('create from aDocs; apply LSI functions IDF, None, Cosine; extract 20 topics; show topics table; thesaurus for bell and ringer.', lang => "Raku")
# my $lsaObj = ML::LatentSemanticAnalyzer.new
# .make-document-term-matrix(docs=>aDocs,
# stop-words=>Whatever,
# stemming-rules=>Whatever,
# min-length=>3)
# .apply-term-weight-functions(global-weight-func=>"IDF",
# local-weight-func=>"None",
# normalizer-func=>"Cosine")
# .extract-topics(number-of-topics=>20, min-number-of-documents-per-term=>20, method=>"LSI", max-steps=>16)
# .echo-topics-interpretation(number-of-terms=>10, wide-form=>True)
# .echo-statistical-thesaurus(terms=>["bell", "ringer"],
# wide-form=>True,
# number-of-nearest-neighbors=>12,
# method=>"cosine",
# echo-function=>&put)
Implementation details
- The initial version was translated to Raku from the Python package "LatentSemanticAnalyzer", [AAp3].
- Multiple changes of the initial translation had to be made:
- Proper use of the (fast)
Math::SparseMatrix::NativeAdapter matrices - Proper topic extraction implementation (using SVD)
- Correct statistical thesaurus shaping
- Using "ML::SparseMatrixRecommender" for statistical thesaurus with Cosine distance
- Refactoring by moving multiple subs to
ML::LatentSemanticAnalyzer::Utilities - Correct (simplistic) resources data ingestion
- Correct automatic topic names derivation
- Profiling and re-implementation of
impose-row-names and impose-column-names in "Math::SparseMatrix" - Fixing a bug "Math::SparseMatrix" related to LSI application using a global weights list
- (Other changes...)
- Testing against Python and Mathematica implementations with the same data and parameters.
References
Articles
[AA1] Anton Antonov,
"A monad for Latent Semantic Analysis workflows",
(2019),
MathematicaForPrediction at WordPress.
[AA2] Anton Antonov,
"Random mandalas deconstruction in R, Python, and Mathematica",
(2022),
MathematicaForPrediction at WordPress.
Python, R, and Wolfram Language packages
[AAp1] Anton Antonov,
Monadic Latent Semantic Analysis Mathematica package,
(2017),
MathematicaForPrediction at GitHub.
[AAp2] Anton Antonov,
Latent Semantic Analysis Monad in R
(2019),
R-packages at GitHub/antononcube.
[AAp3] Anton Antonov,
LatentSemanticAnalyzer, Python package,
(2021-2026),
PyPI.
[AAp4] Anton Antonov,
RandomMandala, Python package,
(2021),
PyPI.
Raku packages
[AAp5] Anton Antonov,
Math::SparseMatrix, Raku package,
(2024-2026),
GitHub/antononcube.
[AAp6] Anton Antonov,
ML::SparseMatrixRecommender, Raku package,
(2025),
GitHub/antononcube.
[AAp7] Anton Antonov,
Data::Generators, Raku package,
(2021-2025),
GitHub/antononcube.
[AAp8] Anton Antonov,
DSL::English::LatentSemanticAnalysisWorkflows, Raku package,
(2020-2024),
GitHub/antononcube.
[AAp9] Anton Antonov,
ML::NLPTemplateEngine, Raku package,
(2023-2025),
GitHub/antononcube.
Repositories
[AAr1] Anton Antonov,
"Random mandalas deconstruction with R, Python, and Mathematica" presentation project,
(2022)
SimplifiedMachineLearningWorkflows-book at GitHub/antononcube.
[AAr2] Anton Antonov,
"Raku for Prediction" book project,
(2021-2022),
GitHub/antononcube.
Videos
[AAv1] Anton Antonov,
"TRC 2022 Implementation of ML algorithms in Raku",
(2022),
Anton A. Antonov's channel at YouTube.
[AAv2] Anton Antonov,
"Raku for Prediction",
(2021),
The Raku Conference (TRC) at YouTube.
[AAv3] Anton Antonov,
"NLP Template Engine, Part 1",
(2021),
Anton A. Antonov's channel at YouTube.
[AAv4] Anton Antonov
"Random Mandalas Deconstruction in R, Python, and Mathematica (Greater Boston useR Meetup, Feb 2022)",
(2022),
Anton A. Antonov's channel at YouTube.