SYNOPSIS
Sparky is flexible and minimalist continuous integration server written in Raku.
Sparky features:
- Defining builds times in crontab style
- Triggering builds using external APIs and custom logic
- Build scenarios are defined as Raku scripts with support of Sparrow6 DSL
- CICD code could be extended using various scripting languages
- Everything is kept in SCM repository - easy to port, maintain and track changes
- Builds gets run in one of 3 flavors - 1) on localhost 2) on remote machines via ssh 3) on docker instances
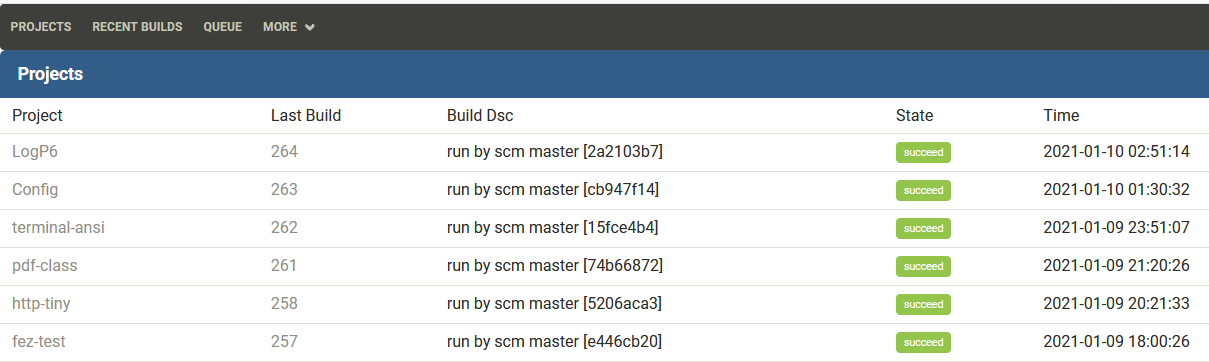
- Nice web UI to run build and read reports
Build status

Sparky workflow in 4 lines:
$ sparkyd # run Sparky daemon to build your projects
$ cron run # run Sparky CI UI to see build statuses and reports
$ nano ~/.sparky/projects/my-project/sparrowfile # write a build scenario
$ firefox 127.0.0.1:3000 # run builds and get reports
Installation
$ sudo apt-get install sqlite3
$ git clone https://github.com/melezhik/sparky.git
$ cd sparky && zef install .
Setup
Run database initialization script to populate database schema:
$ raku db-init.raku
Running daemon
Run ( see also Setting path section ) sparky daemon to dispatch jobs:
$ sparkyd
Sparky daemon traverses sub directories found at the project root directory.
For every directory found initiate build process invoking sparky worker ( sparky-runner.raku ).
Sparky root directory default location is ~/.sparky/projects.
Once all the sub directories gets passed, sparky daemon sleeps for $timeout seconds.
A timeout option allows to balance a load on your system.
You can change a timeout by applying --timeout parameter when running sparky daemon:
$ sparkyd --timeout=600 # sleep 10 minutes
- You can also set a timeout by using
SPARKY_TIMEOUT environment variable:
$ SPARKY_TIMEOUT=30 sparkyd ...
Running sparky in demonized mode.
At the moment sparky can't demonize itself, as temporary workaround use linux nohup command:
$ nohup sparkyd &
To install sparkyd as a systemd unit:
$ nano utils/install-sparky-web-systemd.raku # change working directory and user
$ sparrowdo --sparrowfile=utils/install-sparkyd-systemd.raku --no_sudo --localhost
Setting path
* sparkyd should be in your PATH, usually you need to export PATH=~/.raku/bin:$PATH after zef install .
Sparky Web UI
And finally Sparky has a simple web UI to show builds statuses and reports.
To run Sparky CI web app:
$ cro run
To install Sparky CI web app as a systemd unit:
$ nano utils/install-sparky-web-systemd.raku # change working directory, user and root directory
$ sparrowdo --sparrowfile=utils/install-sparky-web-systemd.raku --no_sudo --localhost
Creating first sparky project
Sparky project is just a directory located at the sparky root directory:
$ mkdir ~/.sparky/projects/teddy-bear-app
Build scenario
Sparky is built on top of Sparrow/Sparrowdo, read Sparrowdo
to know how to write Sparky scenarios.
Here is a short example.
Git check out a Raku project, install dependencies and run unit tests:
$ nano ~/.sparky/projects/teddy-bear-app/sparrowfile
And add content like this:
directory "project";
git-scm 'https://github.com/melezhik/rakudist-teddy-bear.git', %(
to => "project",
);
zef "{%*ENV<PWD>}/project", %(
depsonly => True
);
zef 'TAP::Harness App::Prove6';
bash 'prove6 -l', %(
debug => True,
cwd => "{%*ENV<PWD>}/project/"
);
By default the build scenario gets executed on the same machine you run Sparky at, but you can change this
to any remote host setting Sparrowdo related parameters in the sparky.yaml file:
$ nano ~/.sparky/projects/teddy-bear-app/sparky.yaml
And define worker configuration:
sparrowdo:
host: '192.168.0.1'
ssh_private_key: /path/to/ssh_private/key.pem
ssh_user: sparky
no_index_update: true
sync: /tmp/repo
You can read about the all available parameters in Sparrowdo documentation.
Skip bootstrap
Sparrowdo bootstrap takes a while, if you don't need bootstrap ( sparrow client is already installed at a target host )
use bootstrap: false option:
sparrowdo:
bootstrap: false
Purging old builds
To remove old build set keep_builds parameter in sparky.yaml:
$ nano ~/.sparky/projects/teddy-bear-app/sparky.yaml
Put number of past builds to keep:
keep_builds: 10
That makes Sparky remove old build and only keep last keep_builds builds.
Run by cron
It's possible to setup scheduler for Sparky builds, you should define crontab entry in sparky yaml file.
for example to run a build every hour at 30,50 or 55 minute say this:
$ nano ~/.sparky/projects/teddy-bear-app/sparky.yaml
With this schedule:
crontab: "30,50,55 * * * *"
Follow Time::Crontab documentation on crontab entries format.
Manual run
If you want to build a project from web UI, use allow_manual_run:
$ nano ~/.sparky/projects/teddy-bear-app/sparky.yaml
And activate manual run:
allow_manual_run: true
Trigger build by SCM changes
** warning ** - the feature is not properly tested, feel free to post issues or suggestions
To trigger Sparky builds on SCM changes, define scm section in sparky.yaml file:
scm:
url: $SCM_URL
branch: $SCM_BRANCH
Where:
url - git URLbranch - git branch, optional, default value is master
For example:
scm:
url: https://github.com/melezhik/rakudist-teddy-bear.git
branch: master
Once a build is triggered one needs to handle build environment leveraging tags()<SCM_*> objects:
directory "scm";
say "current commit is: {tags()<SCM_SHA>}";
git-scm tags()<SCM_URL>, %(
to => "scm",
branch => tags<SCM_BRANCH>
);
bash "ls -l {%*ENV<PWD>}/scm";
Disable project
You can disable project builds by setting disable option to true:
$ nano ~/.sparky/projects/teddy-bear-app/sparky.yaml
disabled: true
It's handy when you start a new project and don't want to add it into build pipeline.
Downstream projects
You can run downstream projects by setting downstream field at the upstream project sparky.yaml file:
$ nano ~/.sparky/projects/main/sparky.yaml
downstream: downstream-project
Sparky triggering protocol (STP)
Sparky Triggering Protocol allows to trigger builds automatically by just creating files with build parameters
in special format:
$ nano $project/.triggers/foo-bar-baz
File has to be located in project .trigger directory.
A content of the file should Raku code returning a Hash:
{
description => "Build app",
cwd => "/path/to/working/directory",
sparrowdo => %(
localhost => True,
no_sudo => True,
conf => "/path/to/file.conf"
)
}
Sparky daemon parses files in .triggers and launch build per every file, removing file afterwards,
this process is called file triggering.
To separate different builds just create trigger files with unique names inside $project/.trigger directory.
STP allows to create supplemental APIs to implement more complex and custom build logic, while keeping Sparky itself simple.
Trigger attributes
Those keys could be used in trigger Hash. All they are optional.
cwd
Directory where sparrowfile is located, when a build gets run, the process will change to this directory.
description
Arbitrary text description of build
sparrowdo
Options for sparrowdo run, for example:
%(
host => "foo.bar",
ssh_user => "admin",
tags => "prod,backend"
)
Should follow the format of sparky.yaml, sparrowdo section
A unique key
Sparky plugins
Sparky plugins are extensions points to add extra functionality to Sparky builds.
These are Raku modules get run after a Sparky project finishes or in other words when a build is completed.
To use Sparky plugins you should:
Install Sparky plugins
You should install a module on the same server where you run Sparky at. For instance:
$ zef install Sparky::Plugin::Email # Sparky plugin to send email notifications
In project's sparky.yaml file define plugins section, it should be list of Plugins and its configurations.
For instance:
$ cat sparky.yaml
That contains:
plugins:
- Sparky::Plugin::Email:
parameters:
subject: "I finished"
to: "happy@user.email"
text: "here will be log"
- Sparky::Plugin::Hello:
parameters:
name: Sparrow
Creating Sparky plugins
Technically speaking Sparky plugins should be just Raku modules.
For instance, for mentioned module Sparky::Plugin::Email we might have this header lines:
use v6;
unit module Sparky::Plugin::Hello;
That is it.
The module should have run routine which is invoked when Sparky processes a plugin:
our sub run ( %config, %parameters ) {
}
As we can see the run routine consumes its parameters as Raku Hash, these parameters are defined at mentioned sparky.yaml file,
at plugin parameters: section, so this is how you might handle them:
sub run ( %config, %parameters ) {
say "Hello " ~ %parameters<name>;
}
You can use %config Hash to access Sparky guts:
%config<project> - the project name%config<build-id> - the build number of current project build%cofig<build-state> - the state of the current build
For example:
sub run ( %config, %parameters ) {
say "build id is: " ~ %parameters<build-id>;
}
Alternatively you may pass some predefined parameters plugins:
- %PROJECT% - equivalent of
%config<project> - %BUILD-STATE% - equivalent of
%config<build-state> - %BUILD-ID% - equivalent of
%config<build-id>
For example:
$ cat sparky.yaml
That contains:
plugins:
- Sparky::Plugin::Hello:
parameters:
name: Sparrow from project %PROJECT%
Limit plugin run scope
You can defined when to run plugin, here are 3 run scopes:
anytime - run plugin irrespective of a build state. This is default valuesuccess - run plugin only if build has succeededfail - run plugin only if build has failed
Scopes are defined at run_scope: parameter:
- Sparky::Plugin::Hello:
run_scope: fail
parameters:
name: Sparrow
An example of Sparky plugins
An example Sparky plugins are:
Command line client
You can build the certain project using sparky command client called sparky-runner.raku:
$ sparky-runner.raku --dir=/home/user/.sparky/projects/teddy-bear-app
Or just:
$ cd ~/.sparky/projects/teddy-bear-app && sparky-runner.raku
Sparky runtime parameters
All this parameters could be overridden by command line ( --root, --work-root )
Root directory
This is sparky root directory, or directory where Sparky looks for the projects to get built:
~/.sparky/projects/
Work directory
This is working directory where sparky might place some stuff, useless at the moment:
~/.sparky/work
Environment variables
SPARKY_SKIP_CRON
You can disable cron check to run project forcefully, by setting SPARKY_SKIP_CRON environment variable:
$ export SPARKY_SKIP_CRON=1 && sparkyd
SPARKY_ROOT
Sets the sparky root directory
SPARKY_HTTP_ROOT
Set sparky web application http root. Useful when proxy application through Nginx:
SPARKY_HTTP_ROOT='/sparky' cro run
SPARKY_TIMEOUT
Sets timeout for sparky workers, see Running daemon section.
Running under other databases engines (MySQL, PostgreSQL)
By default Sparky uses sqlite as database engine, which makes it easy to use when developing.
However sqlite has limitation on transactions locking whole database when doing inserts/updates (Database Is Locked errors).
if you prefer other databases here is guideline.
Create sparky configuration file
You should defined database engine and connection parameters, say we want to use MySQL:
$ nano ~/sparky.yaml
With content:
database:
engine: mysql
host: $dbhost
port: $dbport
name: $dbname
user: $dbuser
pass: $dbpassword
For example:
database:
engine: mysql
host: "127.0.0.1"
port: 3306
name: sparky
user: sparky
pass: "123"
Installs dependencies
Depending on platform it should be client needed for your database API, for example for Debian we have to:
$ sudo yum install mysql-client
Creating database user, password and schema
DB init script will generate database schema, provided that user defined and sparky configuration file has access to
the database:
$ raku db-init.raku
That is it, now sparky runs under MySQL!
Change UI theme
Sparky uses Bulma as a CSS framework, you can easily change the theme
through sparky configuration file:
$ nano ~/sparky.yaml
And choose your theme:
ui:
theme: cosmo
The list of available themes is on https://jenil.github.io/bulmaswatch/
HTTP API
Trigger builds
Trigger a project's build
POST /build/project/$project
Returns $key - unique build identificator
Build status
Get project's status ( image/status of the last build ):
GET /status/$project/$key
Returns $status:
Badges
Get project's badge ( image/status of the project's last build ):
GET /badge/$project
Build report
Get build report in raw text format
GET /report/raw/$project/$key
Examples
Examples of sparky configurations could be found in a examples/ folder.
See also
Author
Alexey Melezhik