Data Query Workflows




Introduction
This Raku (Perl 6) package has grammar and action classes for the parsing and interpretation of natural
Domain Specific Language (DSL) commands that specify data queries in the style of Standard Query Language (SQL) or
RStudio's library tidyverse.
The interpreters (actions) have as targets different programming languages (and packages in them.)
The currently implemented programming-language-and-package targets are:
Julia::DataFrames, Mathematica, Python::pandas, R::base, R::tidyverse, Raku::Reshapers.
There are also interpreters to natural languages: Bulgarian, English, Korean, Russian, Spanish.
Installation
Zef ecosystem:
zef install DSL::English::DataQueryWorkflows
GitHub:
zef install https://github.com/antononcube/Raku-DSL-English-DataQueryWorkflows.git
Current state
The following diagram:
- Summarizes the data wrangling capabilities envisioned for this package
- Represents the Raku parsers and interpreters in this package with the hexagon
- Indicates future plans with dashed lines
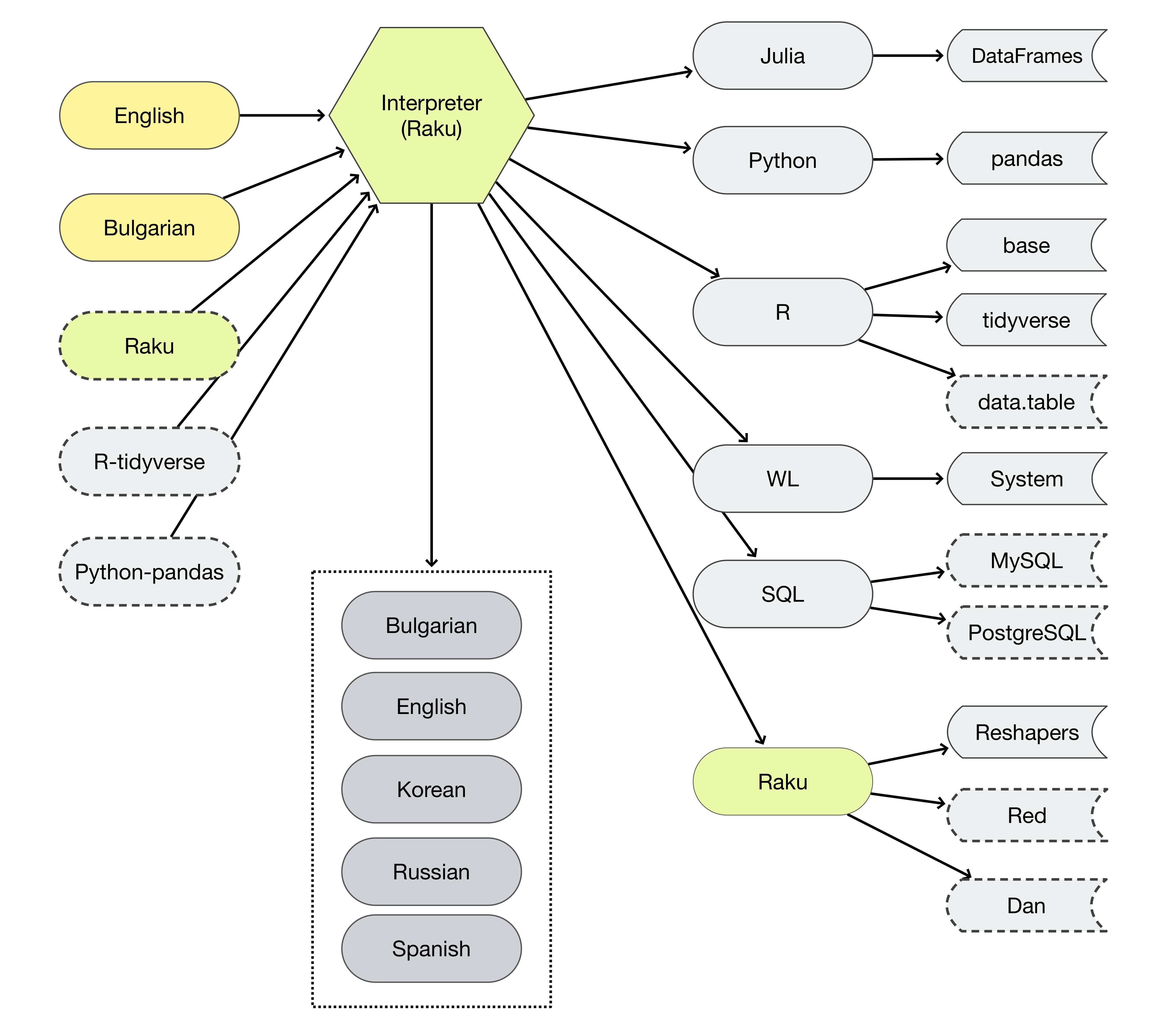
Remark: The grammar of this package is extended to parse Bulgarian DSL commands
with the package
"DSL::Bulgarian",
[AAp5].
Workflows considered
The following flow-chart encompasses the data transformations workflows we consider:
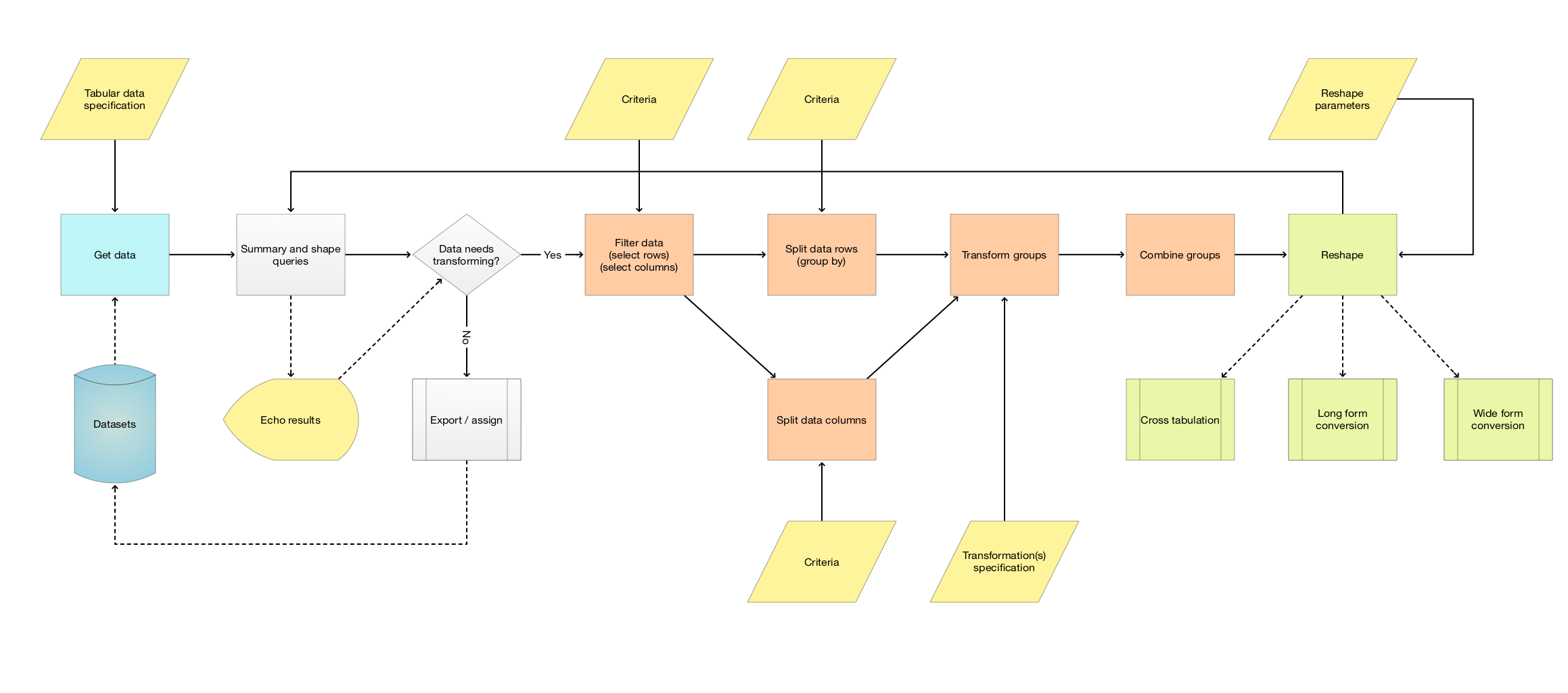
Here are some properties of the methodology / flow chart:
- The flow chart is for tabular datasets, or for lists (arrays) or dictionaries (hashes) of tabular datasets
- In the flow chart only the data loading and summary analysis are not optional
- All other steps are optional
- Transformations like inner-joins are represented by the block “Combine groups”
- It is assumed that in real applications several iterations (loops) have to be run over the flow chart
In the world of the programming language R the orange blocks represent the so called
Split-Transform-Combine pattern;
see the article "The Split-Apply-Combine Strategy for Data Analysis" by Hadley Wickham, [HW1].
For more data query workflows design details see the article
"Introduction to data wrangling with Raku",
[AA1] or its translation (and upgrade) in Bulgarian, [AA2].
Examples
Here is example code:
use DSL::English::DataQueryWorkflows;
say ToDataQueryWorkflowCode('select mass & height', 'R-tidyverse');
# dplyr::select(mass, height)
Here is a longer data wrangling command:
my $command = 'use starwars;
select species, mass & height;
group by species;
arrange by the variables species and mass descending';
# use starwars;
# select species, mass & height;
# group by species;
# arrange by the variables species and mass descending
Here we translate that command into executable code for Julia, Mathematica, Python, R, and Raku:
{say $_.key, ":\n", $_.value, "\n"} for <Julia Mathematica Python R R::tidyverse Raku>.map({ $_ => ToDataQueryWorkflowCode($command, $_ ) });
# Julia:
# obj = starwars
# obj = obj[ : , [:species, :mass, :height]]
# obj = groupby( obj, [:species] )
# obj = sort( obj, [:species, :mass], rev=true )
#
# Mathematica:
# obj = starwars
# obj = Map[ KeyTake[ #, {"species", "mass", "height"} ]&, obj]
# obj = GroupBy[ obj, #["species"]& ]
# obj = ReverseSortBy[ #, {#["species"], #["mass"]}& ]& /@ obj
#
# Python:
# obj = starwars.copy()
# obj = obj[["species", "mass", "height"]]
# obj = obj.groupby(["species"])
# obj = obj.sort_values( ["species", "mass"], ascending = False )
#
# R:
# obj <- starwars ;
# obj <- obj[, c("species", "mass", "height")] ;
# obj <- split( x = obj, f = "species" ) ;
# obj <- obj[ rev(order(obj[ ,c("species", "mass")])), ]
#
# R::tidyverse:
# starwars %>%
# dplyr::select(species, mass, height) %>%
# dplyr::group_by(species) %>%
# dplyr::arrange(desc(species, mass))
#
# Raku:
# $obj = starwars ;
# $obj = select-columns($obj, ("species", "mass", "height") ) ;
# $obj = group-by($obj, "species") ;
# $obj = $obj>>.sort({ ($_{"species"}, $_{"mass"}) })>>.reverse
Here we translate to other human languages:
{say $_.key, ":\n", $_.value, "\n"} for <Bulgarian English Korean Russian Spanish>.map({ $_ => ToDataQueryWorkflowCode($command, $_ ) });
# Bulgarian:
# използвай таблицата: starwars
# избери колоните: "species", "mass", "height"
# групирай с колоните: species
# сортирай в низходящ ред с колоните: "species", "mass"
#
# English:
# use the data table: starwars
# select the columns: "species", "mass", "height"
# group by the columns: species
# sort in descending order with the columns: "species", "mass"
#
# Korean:
# 테이블 사용: starwars
# "species", "mass", "height" 열 선택
# 열로 그룹화: species
# 열과 함께 내림차순으로 정렬: "species", "mass"
#
# Russian:
# использовать таблицу: starwars
# выбрать столбцы: "species", "mass", "height"
# групировать с колонками: species
# сортировать в порядке убывания по столбцам: "species", "mass"
#
# Spanish:
# utilizar la tabla: starwars
# escoger columnas: "species", "mass", "height"
# agrupar con columnas: "species"
# ordenar en orden descendente con columnas: "species", "mass"
Additional examples can be found in this file:
DataQueryWorkflows-examples.raku.
Command line interface
The package provides the Command Line Interface (CLI) program ToDataQueryWorkflowCode.
Here is its usage message:
> ToDataQueryWorkflowCode --help
Translates natural language commands into data transformations programming code.
Usage:
ToDataQueryWorkflowCode [-t|--target=<Str>] [-l|--language=<Str>] [-f|--format=<Str>] [-c|--clipboard-command=<Str>] <command> -- Main CLI signature.
ToDataQueryWorkflowCode [-l|--language=<Str>] [-f|--format=<Str>] [-c|--clipboard-command=<Str>] <target> <command> -- Easier target specification.
ToDataQueryWorkflowCode [-t|--target=<Str>] [-l|--language=<Str>] [-f|--format=<Str>] [-c|--clipboard-command=<Str>] [<words> ...] -- Command given as a sequence of words.
<command> A string with one or many commands (separated by ';').
-t|--target=<Str> Target (programming language with optional library spec.) [default: 'Whatever']
-l|--language=<Str> The natural language to translate from. [default: 'English']
-f|--format=<Str> The format of the output, one of 'Whatever', 'code', 'hash', or 'raku'. [default: 'Whatever']
-c|--clipboard-command=<Str> Clipboard command to use. [default: 'Whatever']
<target> Programming language.
[<words> ...] Words of a data query.
Details:
If --target is 'Whatever' then:
1. It is attempted to use the environmental variable RAKU_DSL_DATAQUERYWORKFLOWS_TARGET
2. If RAKU_DSL_DATAQUERYWORKFLOWS_TARGET is not defined then 'R::tidyverse' is used.
If --clipboard-command is the empty string then no copying to the clipboard is done.
If --clipboard-command is 'Whatever' then:
1. It is attempted to use the environment variable CLIPBOARD_COPY_COMMAND.
If CLIPBOARD_COPY_COMMAND is defined and it is the empty string then no copying to the clipboard is done.
2. If the variable CLIPBOARD_COPY_COMMAND is not defined then:
- 'pbcopy' is used on macOS
- 'clip.exe' on Windows
- 'xclip -selection clipboard' on Linux.
Here is an example invocation:
> ToDataQueryWorkflowCode Python "use the dataset dfTitanic; group by passengerSex; show counts"
obj = dfTitanic.copy()
obj = obj.groupby(["passengerSex"])
print(obj.size())
Testing
There are three types of unit tests for:
Parsing abilities; see example
Interpretation into correct expected code; see example
Data transformation correctness; see tests in:
The unit tests R-package [AAp2] can be used to test both R and Python translations and equivalence between them.
There is a similar WL package, [AAp3].
(The WL unit tests package can have unit tests for Julia, Python, R -- not implemented yet.)
On naming of translation packages
WL has a System context where usually the built-in functions reside. WL adepts know this, but others do not.
(Every WL package provides a context for its functions.)
My naming convention for the translation files so far is <programming language>::<package name>.
And I do not want to break that invariant.
Knowing the package is not essential when invoking the functions. For example ToDataQueryWorkflowCode[_,"R"] produces
same results as ToDataQueryWorkflowCode[_,"R-base"], etc.
Versions
The original version of this Raku package was developed/hosted at
[ AAp1 ].
A dedicated GitHub repository was made in order to make the installation with Raku's zef more direct.
(As shown above.)
TODO
DONE Implement SQL actions.
TODO Implement Swift::TabularData actions.
TODO Implement Raku::Dan actions.
TODO Make sure "round trip" translations work.
References
Articles
[AA1] Anton Antonov,
"Introduction to data wrangling with Raku",
(2021),
RakuForPrediction at WordPress.
[AA2] Anton Antonov,
"Увод в обработката на данни с Raku",
(2022),
RakuForPrediction at WordPress.
[HW1] Hadley Wickham,
"The Split-Apply-Combine Strategy for Data Analysis",
(2011),
Journal of Statistical Software.
Notebooks
[AAn1] Anton Antonov,
"Standard Data Wrangling Commands (in Raku)",
(2022),
Raku-DSL-English-DataQueryWorkflows at GitHub.
(Markdown notebook.)
[AAn2] Anton Antonov,
"Standard Data Wrangling Commands (in Python)",
(2022),
RakuForPrediction-book at GitHub.
(Jypyter notebook.)
Packages
[AAp1] Anton Antonov,
Data Query Workflows Raku Package
,
(2020),
ConversationalAgents at GitHub/antononcube.
[AAp2] Anton Antonov,
Data Query Workflows Tests,
(2020),
R-packages at GitHub/antononcube.
[AAp3] Anton Antonov,
Data Query Workflows Mathematica Unit Tests,
(2020),
ConversationalAgents at GitHub/antononcube.
[AAp4] Anton Antonov,
Data Query Workflows Python Unit Tests,
(2020),
ConversationalAgents at GitHub/antononcube.
[AAp5] Anton Antonov,
DSL::Bulgarian Raku package,
(2022),
GitHub/antononcube.
Videos
[AAv1] Anton Antonov,
"Multi-language Data-Wrangling Conversational Agent",
(2020),
Wolfram Technology Conference 2020, YouTube/Wolfram.
[AAv2] Anton Antonov,
"Raku for Prediction",
(2021),
The Raku Conference 2021.
[AAv3] Anton Antonov,
"Doing it like a Cro (Raku data wrangling Shortcuts demo)",
(2021),
Anton Antonov's channel at YouTube.
[AAv4] Anton Antonov,
"FOSDEM2022 Multi language Data Wrangling and Acquisition Conversational Agents (in Raku)",
(2022),
Anton Antonov's channel at YouTube.
[AAv5] Anton Antonov,
"Implementing Machine Learning algorithms in Raku" at TRC-2022
(2022),
The Raku Conference 2022.