LLM::Functions




Introduction
This Raku package provides functions and function objects to access, interact, and utilize
Large Language Models (LLMs), like
OpenAI,
Gemini,
MistralAI,
and
Ollama.
For more details how the concrete LLMs are accessed see the packages
"WWW::OpenAI", [AAp2],
"WWW::MistralAI", [AAp9],
"WWW::Gemini", [AAp11], and
"WWW::Ollama", [AAp12].
The LLM functions built by this package can have evaluators that use "sub-parsers" -- see
"Text::SubParsers", [AAp4].
The primary motivation to have handy, configurable functions for utilizing LLMs
came from my work on the packages
"ML::FindTextualAnswer", [AAp6], and
"ML::NLPTemplateEngine", [AAp7].
A very similar system of functionalities is developed by Wolfram Research Inc.;
see the paclet
"LLMFunctions", [WRIp1].
For well curated and instructive examples of LLM prompts see the
Wolfram Prompt Repository.
Many of those prompts (more than 220) are available in Raku and Python --
see "LLM::Prompts", [AAp8], and
"LLMPrompts", [AAp10], respectively.
The article
"Generating documents via templates and LLMs", [AA1],
shows an alternative way of streamlining LLMs usage. (Via Markdown, Org-mode, or Pod6 templates.)
Installation
Package installations from both sources use zef installer
(which should be bundled with the "standard" Rakudo installation file.)
To install the package from Zef ecosystem use the shell command:
zef install LLM::Functions
To install the package from the GitHub repository use the shell command:
zef install https://github.com/antononcube/Raku-LLM-Functions.git
Design
"Out of the box"
"LLM::Functions" uses
"WWW::OpenAI", [AAp2],
"WWW::MistralAI", [AAp9],
"WWW::Gemini", [AAp11], and
"WWW::Ollama", [AAp12],
Other LLM access packages can be utilized via appropriate LLM configurations.
Configurations:
- Are instances of the class
LLM::Functions::Configuration - Are used by instances of the class
LLM::Functions::Evaluator - Can be converted to Hash objects (i.e. have a
.Hash method)
New LLM functions are constructed with the function llm-function.
The function llm-function:
- Has the option "llm-evaluator" that takes evaluators, configurations, or string shorthands as values
- Returns anonymous functions (that access LLMs via evaluators/configurations.)
- Gives result functions that can be applied to different types of arguments depending on the first argument
- Can take a (sub-)parser argument for post-processing of LLM results
- Takes as a first argument a prompt that can be a:
- String
- Function with positional arguments
- Function with named arguments
Here is a sequence diagram that follows the steps of a typical creation procedure of
LLM configuration- and evaluator objects, and the corresponding LLM-function that utilizes them:
sequenceDiagram
participant User
participant llmfunc as llm-function
participant llmconf as llm-configuration
participant LLMConf as LLM configuration
participant LLMEval as LLM evaluator
participant AnonFunc as Anonymous function
User ->> llmfunc: ・prompt<br>・conf spec
llmfunc ->> llmconf: conf spec
llmconf ->> LLMConf: conf spec
LLMConf ->> LLMEval: wrap with
LLMEval ->> llmfunc: evaluator object
llmfunc ->> AnonFunc: create with:<br>・evaluator object<br>・prompt
AnonFunc ->> llmfunc: handle
llmfunc ->> User: handle
Here is a sequence diagram for making a LLM configuration with a global (engineered) prompt,
and using that configuration to generate a chat message response:
sequenceDiagram
participant WWWOpenAI as WWW::OpenAI
participant User
participant llmfunc as llm-function
participant llmconf as llm-configuration
participant LLMConf as LLM configuration
participant LLMChatEval as LLM chat evaluator
participant AnonFunc as Anonymous function
User ->> llmconf: engineered prompt
llmconf ->> User: configuration object
User ->> llmfunc: ・prompt<br>・configuration object
llmfunc ->> LLMChatEval: configuration object
LLMChatEval ->> llmfunc: evaluator object
llmfunc ->> AnonFunc: create with:<br>・evaluator object<br>・prompt
AnonFunc ->> llmfunc: handle
llmfunc ->> User: handle
User ->> AnonFunc: invoke with<br>message argument
AnonFunc ->> WWWOpenAI: ・engineered prompt<br>・message
WWWOpenAI ->> User: LLM response
Configurations
OpenAI-based
Here is the default, OpenAI-based configuration:
use LLM::Functions;
llm-configuration('OpenAI');
# LLM::Configuration(:name("openai"), :model("gpt-3.5-turbo-instruct"), :module("WWW::OpenAI"), :max-tokens(2048))
Here is the ChatGPT-based configuration:
llm-configuration('ChatGPT')
# LLM::Configuration(:name("chatgpt"), :model("gpt-4.1-mini"), :module("WWW::OpenAI"), :max-tokens(2048))
Remark: llm-configuration(Whatever) is equivalent to llm-configuration('OpenAI').
Remark: Both the "OpenAI" and "ChatGPT" configuration use functions of the package "WWW::OpenAI", [AAp2].
The "OpenAI" configuration is for text-completions;
the "ChatGPT" configuration is for chat-completions.
Gemini-based
Here is the default Gemini configuration:
llm-configuration('Gemini')
# LLM::Configuration(:name("gemini"), :model("gemini-2.0-flash-lite"), :module("WWW::Gemini"), :max-tokens(4096))
All configuration elements
To see all elements of an LLM configuration object use the method .Hash. For example:
.say for |llm-configuration('Gemini').Hash
# module => WWW::Gemini
# tools => []
# base-url => https://generativelanguage.googleapis.com/v1beta/models
# evaluator => (Whatever)
# api-key => (Whatever)
# stop-tokens => []
# embedding-function => &GeminiEmbedContent
# max-tokens => 4096
# prompt-delimiter =>
# tool-request-parser => (WhateverCode)
# function => &GeminiGenerateContent
# reasoning-effort => (Whatever)
# prompts => []
# embedding-model => embedding-001
# verbosity => (Whatever)
# tool-response-insertion-function => (WhateverCode)
# images => []
# name => gemini
# argument-renames => {api-key => auth-key, max-tokens => max-output-tokens, stop-tokens => stop-sequences, tool-config => toolConfig}
# total-probability-cutoff => 0
# model => gemini-2.0-flash-lite
# format => values
# examples => []
# temperature => 0.4
# tool-prompt =>
# api-user-id => user:879539693647
Basic usage of LLM functions
Textual prompts
Here we make a LLM function with a simple (short, textual) prompt:
my &func = llm-function('Show a recipe for:');
# LLM::Function(-> $text = "", *%args { #`(Block|5994704893016) ... }, 'chatgpt')
Here we evaluate over a message:
say &func('greek salad');
# Certainly! Here's a classic recipe for a Greek Salad:
#
# ### Greek Salad Recipe
#
# **Ingredients:**
# - 3 medium tomatoes, cut into wedges
# - 1 cucumber, sliced
# - 1 green bell pepper, sliced into rings
# - 1 small red onion, thinly sliced
# - 200g (about 7 oz) feta cheese, cut into cubes or crumbled
# - A handful of Kalamata olives
# - 2 tablespoons extra virgin olive oil
# - 1 tablespoon red wine vinegar (optional)
# - 1 teaspoon dried oregano
# - Salt and freshly ground black pepper, to taste
#
# **Instructions:**
# 1. In a large bowl, combine the tomatoes, cucumber, green bell pepper, and red onion.
# 2. Add the Kalamata olives and feta cheese on top.
# 3. Drizzle the olive oil and red wine vinegar over the salad.
# 4. Sprinkle with dried oregano, salt, and pepper.
# 5. Toss gently to combine, being careful not to break up the feta.
# 6. Serve immediately or chill for 15-20 minutes to allow flavors to meld.
#
# Enjoy your fresh and flavorful Greek salad!
Positional arguments
Here we make a LLM function with a function-prompt composed with a dedicated LLM numbers-only prompt and a numeric interpreter of the result:
use LLM::Prompts;
my &func2 = llm-function(
{"How many $^a can fit inside one $^b?" ~ llm-prompt('NumericOnly')},
form => Numeric,
llm-evaluator => 'chatgpt');
# LLM::Function(-> **@args, *%args { #`(Block|5994730572560) ... }, 'chatgpt')
Here were we apply the function:
my $res2 = &func2("tennis balls", "toyota corolla 2010");
# 2307692
Here we show that we got a number:
$res2 ~~ Numeric
# False
Named arguments
Here the first argument is a template with two named arguments:
my &func3 = llm-function(-> :$dish, :$cuisine {"Give a recipe for $dish in the $cuisine cuisine."}, llm-evaluator => 'chatgpt');
# LLM::Function(-> **@args, *%args { #`(Block|5994726508880) ... }, 'chatgpt')
Here is an invocation:
&func3(dish => 'salad', cuisine => 'Russian', max-tokens => 300);
# Certainly! Here's a classic Russian salad recipe called **Olivier Salad**, also known simply as Russian Salad. It's very popular in Russia, especially during celebrations like New Year's.
#
# ### Olivier Salad (Russian Salad) Recipe
#
# #### Ingredients:
# - 4-5 medium potatoes
# - 3 medium carrots
# - 4 eggs
# - 200 grams (7 oz) boiled chicken breast (or ham, or bologna sausage)
# - 1 cup canned peas (drained)
# - 3-4 pickled cucumbers (or dill pickles)
# - 1 small onion (optional)
# - 1 cup mayonnaise
# - Salt and black pepper to taste
#
# #### Instructions:
# 1. **Cook the vegetables and eggs:**
# - Boil the potatoes and carrots with their skins on until tender (about 20-25 minutes).
# - Hard-boil the eggs (about 10 minutes).
# - Let them cool, then peel the potatoes, carrots, and eggs.
#
# 2. **Chop ingredients:**
# - Dice the potatoes, carrots, eggs, chicken breast, and pickles into small, uniform cubes.
# - Finely chop the onion if using.
#
# 3. **Combine ingredients:**
# - In a large bowl, mix the diced potatoes, carrots, eggs, chicken, pickles, peas, and onion.
#
# 4. **Add mayonnaise:**
# - Add the mayonnaise to the bowl and gently mix everything together until well combined.
# - Season with salt and
LLM example functions
The function llm-example-function can be given a training set of examples in order
to generating results according to the "laws" implied by that training set.
Here a LLM is asked to produce a generalization:
llm-example-function([ 'finger' => 'hand', 'hand' => 'arm' ])('foot')
# Output: leg
Here is an array of training pairs is used:
'Oppenheimer' ==> (["Einstein" => "14 March 1879", "Pauli" => "April 25, 1900"] ==> llm-example-function)()
# Output: April 22, 1904
Here is defined a LLM function for translating WL associations into Python dictionaries:
my &fea = llm-example-function( '<| A->3, 4->K1 |>' => '{ A:3, 4:K1 }');
&fea('<| 23->3, G->33, T -> R5|>');
# Output: { 23:3, G:33, T:R5 }
The function llm-example-function takes as a first argument:
- Single
Pair object of two scalars - Single
Pair object of two Positional objects with the same length - A
Hash - A
Positional object of pairs
Remark: The function llm-example-function is implemented with llm-function and suitable prompt.
Here is an example of using hints:
my &fec = llm-example-function(
["crocodile" => "grasshopper", "fox" => "cardinal"],
hint => 'animal colors');
say &fec('raccoon');
# Input: raccoon
# Output: panda
Using predefined prompts
Using predefined prompts of the package "LLM::Prompts", [AAp8],
can be very convenient in certain (many) cases.
Here is an example using "Fixed That For You" synthesis:
use LLM::Prompts;
llm-synthesize([llm-prompt('FTFY'), 'Wha is ther population?'])
# What is the population?
Using chat-global prompts
The configuration objects can be given prompts that influence the LLM responses
"globally" throughout the whole chat. (See the second sequence diagram above.)
For detailed examples see the documents:
Chat objects
Here we create chat object that uses OpenAI's ChatGPT:
my $prompt = 'You are a gem expert and you give concise answers.';
my $chat = llm-chat(chat-id => 'gem-expert-talk', conf => 'ChatGPT', :$prompt);
# LLM::Functions::Chat(chat-id = gem-expert-talk, llm-evaluator.conf.name = chatgpt, messages.elems = 0)
$chat.eval('What is the most transparent gem?');
# The most transparent gem is typically considered to be **diamond**, known for its exceptional clarity and brilliance. However, other gems like **white sapphire** and **topaz** can also be highly transparent depending on quality.
$chat.eval('Ok. What are the second and third most transparent gems?');
# After diamond, the second most transparent gem is generally **white sapphire**, and the third is often **topaz**. Both can exhibit excellent clarity and transparency when of high quality.
Here are the prompt(s) and all messages of the chat object:
$chat.say
# Chat: gem-expert-talk
# ⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺
# Prompts: You are a gem expert and you give concise answers.
# ⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺
# role : user
# content : What is the most transparent gem?
# timestamp : 2026-02-06T14:58:56.544963-05:00
# ⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺
# role : assistant
# content : The most transparent gem is typically considered to be **diamond**, known for its exceptional clarity and brilliance. However, other gems like **white sapphire** and **topaz** can also be highly transparent depending on quality.
# timestamp : 2026-02-06T14:58:57.607608-05:00
# ⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺
# role : user
# content : Ok. What are the second and third most transparent gems?
# timestamp : 2026-02-06T14:58:57.619923-05:00
# ⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺⸺
# role : assistant
# content : After diamond, the second most transparent gem is generally **white sapphire**, and the third is often **topaz**. Both can exhibit excellent clarity and transparency when of high quality.
# timestamp : 2026-02-06T14:58:58.699500-05:00
AI-vision functions
Consider this image:
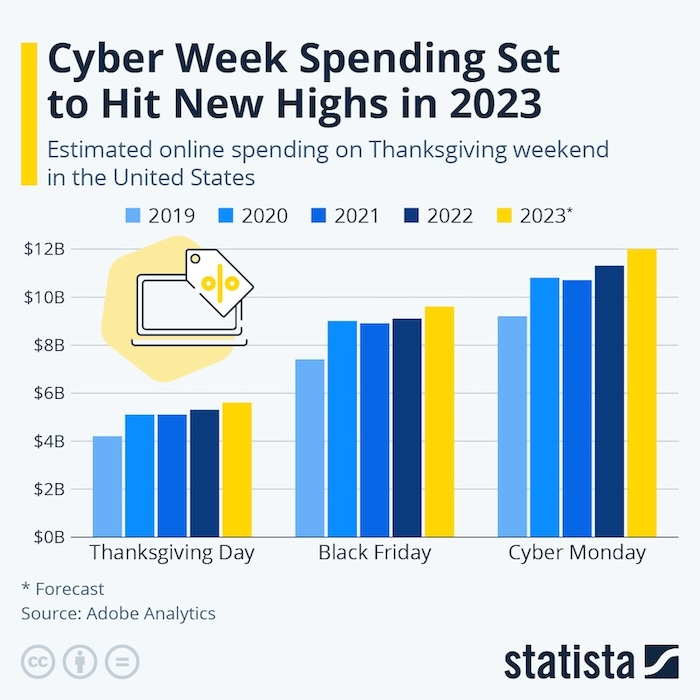
Here we import the image (as a Base64 string):
use Image::Markup::Utilities;
my $url = 'https://raw.githubusercontent.com/antononcube/MathematicaForPrediction/master/MarkdownDocuments/Diagrams/AI-vision-via-WL/0iyello2xfyfo.png';
my $img = image-import($url);
$img.substr(^100)
#  over the URL of the image:
llm-vision-synthesize('Describe the image.', $url);
# The image is a bar chart titled "Cyber Week Spending Set to Hit New Highs in 2023," showing estimated online spending on Thanksgiving weekend in the United States from 2019 to 2023. The chart includes data for Thanksgiving Day, Black Friday, and Cyber Monday.
#
# - **Thanksgiving Day**: Spending increases steadily from 2019 to 2023, with 2023 projected to be the highest.
# - **Black Friday**: Spending shows a gradual increase, with 2023 expected to surpass previous years.
# - **Cyber Monday**: Consistently the highest spending day, with 2023 forecasted to reach new highs.
#
# The bars are color-coded by year: 2019 (light blue), 2020 (medium blue), 2021 (darker blue), 2022 (darkest blue), and 2023 (yellow). The source is Adobe Analytics, and the 2023 data is marked as a forecast.
Remark: Currently, Gemini works with (Base64) images only (and does not with URLs.) OpenAI's vision works with both URLs and images.
The function llm-vision-function uses the same evaluators (configurations, models) as llm-vision-synthesize.
Potential problems
With Gemini with certain wrong configurations we get the error:
error => {code => 400, message => Messages must alternate between authors., status => INVALID_ARGUMENT}
Using the Boolean argument :echo while invoking llm-synthesize (and the other "llm-*" subs) can be useful to identify the sources of the problems.
TODO
- DONE Resources
- See "LLM::Prompts"
- DONE Gather prompts
- DONE Process prompts into a suitable database
- TODO Implementation
- DONE Processing and array of prompts as a first argument
- DONE Prompt class / object / record
- Again, see "LLM::Prompts"
- For retrieval and management of prompts.
- DONE Prompts can be both plain strings or templates / functions.
- DONE Each prompt has associated metadata:
- Type: persona, function, modifier
- Tool/parser
- Keywords
- Contributor?
- Topics: "Advisor bot", "AI Guidance", "For Fun", ...
- DONE Most likely, there would be a separate package "LLM::Prompts", [AAp8].
- CANCELED Random selection of LLM-evaluator
- Currently, the LLM-evaluator of the LLM-functions and LLM-chats is static, assigned at creation.
- This is easily implemented at "top-level."
- DONE Chat class / object
- DONE Include LLaMA
- Just using a different
:$base-url for "ChatGPT" for the configurations.
- DONE Include Gemini
- DONE Separate configuration
- DONE Its own evaluator class
- DONE LLM example function
- DONE First version with the signatures:
@pairs@input => @output- Hint option
- DONE Verify works with OpenAI
- DONE Verify works with PaLM
- Removed in version 0.5.5 since PaLM is obsoleted.
- DONE Verify works with Gemini
- DONE Verify works with Ollama
- DONE Interpreter argument for
llm-function- See the
formatron attribute of LLM::Functions::Evaluator.
- DONE Adding
form option to chat objects evaluator - DONE Implement
llm-embedding function- Generic, universal function for accessing the embeddings of different providers/models.
- DONE Implement LLM-functor class
LLM::Function- DONE Class design & implementation
- DONE Make
&llm-function return functors- And Block-functions based on the option
:$type.
- DONE Implement LLM-tooling infrastructure
- TODO Hook-up LLM-tooling for/in:
- TODO
&llm-synthesize - TODO
&llm-function
- TODO CLI
- TODO Based on Chat objects
- TODO Storage and retrieval of chats
- TODO Has as parameters all attributes of the LLM-configuration objects.
- TODO Documentation
- TODO Detailed parameters description
- TODO Configuration
- TODO Evaluator
- TODO Chat
- DONE Using engineered prompts
- DONE Expand tests in documentation examples
- DONE Conversion of a test file tests into Gherkin specs
- DONE Number game programming
- DONE Man vs Machine
- DONE Machine vs Machine
- DONE Using retrieved prompts
- TODO Longer conversations / chats
References
Articles
[AA1] Anton Antonov,
"Generating documents via templates and LLMs",
(2023),
RakuForPrediction at WordPress.
[ZG1] Zoubin Ghahramani,
"Introducing PaLM 2",
(2023),
Google Official Blog on AI.
Repositories, sites
[MAI1] MistralAI team, MistralAI platform.
[OAI1] OpenAI team, OpenAI platform.
[WRIr1] Wolfram Research, Inc.
Wolfram Prompt Repository.
Packages, paclets
[AAp1] Anton Antonov,
LLM::Functions, Raku package,
(2023),
GitHub/antononcube.
[AAp2] Anton Antonov,
WWW::OpenAI, Raku package,
(2023),
GitHub/antononcube.
[AAp3] Anton Antonov,
WWW::PaLM, Raku package,
(2023),
GitHub/antononcube.
[AAp4] Anton Antonov,
Text::SubParsers, Raku package,
(2023),
GitHub/antononcube.
[AAp5] Anton Antonov,
Text::CodeProcessing, Raku package,
(2021),
GitHub/antononcube.
[AAp6] Anton Antonov,
ML::FindTextualAnswer, Raku package,
(2023),
GitHub/antononcube.
[AAp7] Anton Antonov,
ML::NLPTemplateEngine, Raku package,
(2023),
GitHub/antononcube.
[AAp8] Anton Antonov,
LLM::Prompts, Raku package,
(2023),
GitHub/antononcube.
[AAp9] Anton Antonov,
WWW::MistralAI, Raku package,
(2023),
GitHub/antononcube.
[AAp10] Anton Antonov,
LLMPrompts, Python package,
(2023),
PyPI.org/antononcube.
[AAp11] Anton Antonov,
WWW::Gemini, Raku package,
(2024),
GitHub/antononcube.
[AAp12] Anton Antonov,
WWW::Ollama, Raku package,
(2026),
GitHub/antononcube.
[WRIp1] Wolfram Research, Inc.
LLMFunctions paclet,
(2023),
Wolfram Language Paclet Repository.